4.1. Software Architecture¶
4.1.1. Overview¶
ShakeMap v4 is designed to allow flexibility in the organization of
computing resources. Figure 1 illustrates an
idealized implementation where data preparation, processing, and rendering
all take place within separate computational units. The processing sequence
starts when an earthquake is identified and a decision is made to produce a
ShakeMap. The process shake assemble collects the available information
about the event (origin and rupture parameters, seismic data, etc.) as well
as ShakeMap configuration information (which may include information about the
event’s seismotectonic regime and related choices about GMPE selection), and
produces a file, shake_data.hdf, containing all of these parameters. This
file may be injected into a messaging system, but may also be used locally
by subsequent processes.
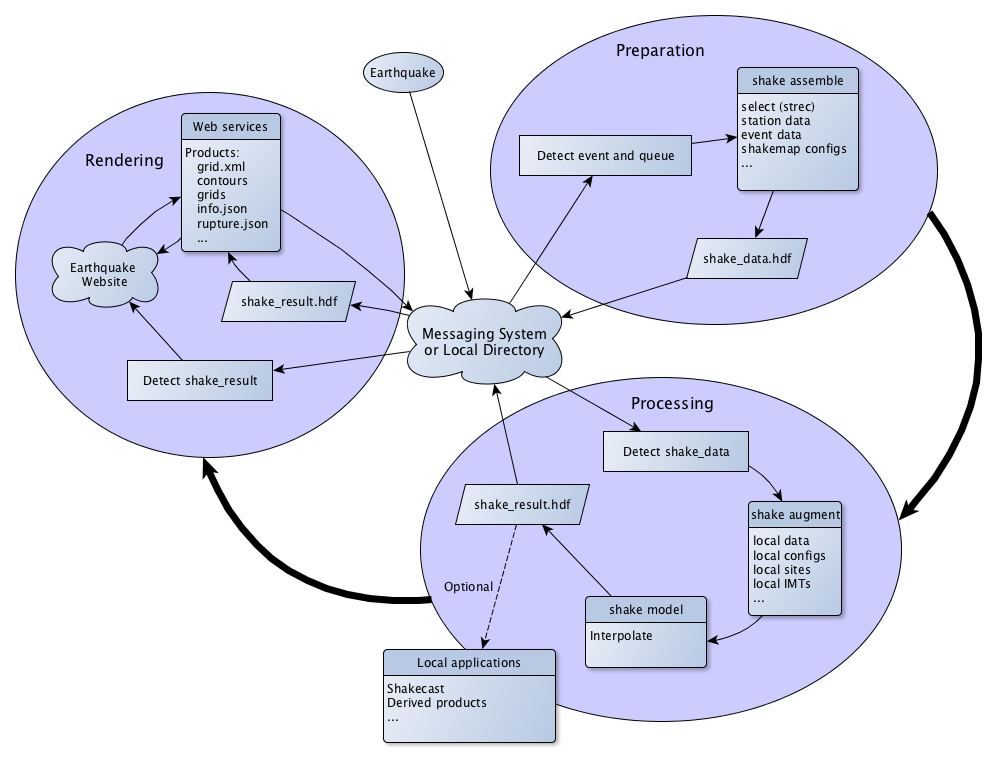
Figure 1: Overview of ShakeMap architecture.¶
The processing continues when shake_data.hdf becomes available. The ShakeMap
process shake model reads shake_data.hdf and produces output in the file
shake_result.hdf. This result can then be fed into a messaging system for
delivery to consumers. Some consumers, however, have more sophisticated
requirements than can be accommodated by simply processing shake_result.hdf
or other generic ShakeMap products.
ShakeCast (Wald et al., 2008), for example, requires
ground motions at a variety of spectral periods and at specific locations that
may not fall on or within the grid produced by the authoritative ShakeMap
system. ShakeCast operators may also have data not available to the
authoritative system. Remote processing systems can receive shake_data.hdf
from a messaging system, and run the program shake augment to add their own
data and configuration choices to those contained in shake_data.hdf
(see Figure 2). They may then run shake model to
generate a shake_result.hdf specific to their needs.
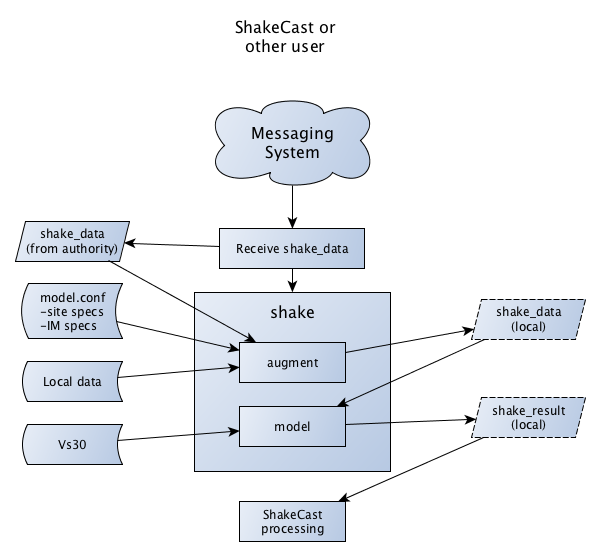
Figure 2: An example of a consumer of the shake_data.hdf product.¶
Rendering begins when shake_result.hdf becomes available. A set of modules
exist (or may be developed) to read shake_result.hdf and produce the variety
of products for which ShakeMap is known.
These shake modules may produce the products locally (i.e., by the same
system that generates shake_result.hdf) and transfer them to consumers via
a messaging system or other means.
An alternative approach, however, is to create a web service that delivers
the products when they are requested. This approach is illustrated in
Figure 3. When the website is notified of the existence
of shake_result.hdf, it can begin the process of creating a “page” for the
event. It requests any necessary products from the web service, which in turn
generates those products from shake_result.hdf (via shake modules). As
products are needed (e.g., from users viewing or requesting downloads) they
are produced on the fly by the web service. Once generated, products may be
cached by the web system to improve performance.
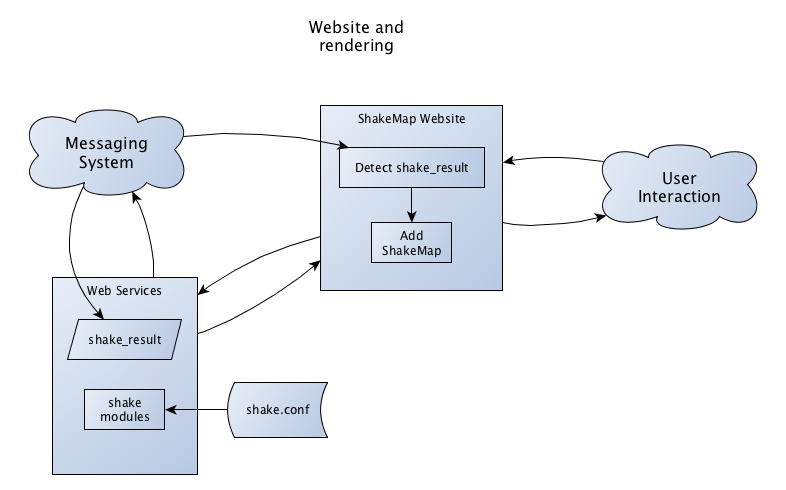
Figure 3: An example of a website using a web service to retrieve products. The web service produces products from shake_result.hdf.¶
Any combination of these approaches (i.e., producing products locally or via a web service) may be developed (e.g., the web service may be designed to collect a subset of ShakeMap products available through a messaging system and deliver them when requested, rather than producing them itself). Thus, the same set of constituent modules are needed, whether the products are delivered directly by the authoritative ShakeMap system or through a web service.
4.1.2. Programs¶
The core components of ShakeMap are a set of command line programs. These programs allow the operator to set up a ShakeMap environment, collect data and configurations into inputs (i.e., shake_data.hdf), and generate ShakeMap grids and their associated products.
4.1.2.1. sm_profile¶
The user will need to run sm_profile at least once to create a ShakeMap
environment, referred to as a ‘profile.’ This environment consists of two
directories – one for event data, and another for configuration files and
associated support products (Vs30 grid, geographic features, etc.) – and a
configuration file that points to them. The profile data resides in a file
called profiles.conf in a subdirectory, .shakemap, of the user’s home
directory. The user may choose another location for the profile file by using
the -f option to sm_profile. Other ShakeMap programs read the profile
information and use it to find event and configuration information. By default,
the install and data paths are located in a directory
[home]/shake_profiles/[profile] where
[home] is the user’s home directory, and [profile] is the name of
the newly-created profile (often “default”). It is advisable, however
to make the data path point to a disk with a large amount of free space
(via either directly setting it when creating the profile, or through the
use of symbolic links).
The data directory (<data_dir>) contains event subdirectories (named
with their event IDs) and their associated subdirectories:
<data_dir>/
<event_id_1>/
current/
event.xml
*_dat.xml
*_fault.txt (or rupture.json)
model.conf (or model_select.conf)
products/
shake_result.hdf
...
shake.log
.backup0001/
event.xml
...
.backup0002/
...
...
<event_id_2>/
...
<event_id_3>/
...
...
The ‘install’ directory (<install_dir>) holds configuration files and
user supplied geographic or other system specific data:
<install_dir>/
config/
model.conf
modules.conf
gmpe_sets.conf
...
mapping/
global_vs30.grd
global_topo.grd
logs/
shake.log
shake.log.<timestamp>
...
<other_directory>/
(additional data files)
...
Macros within the configuration system allow the user to specify the root data and install directories when setting configuration parameters.
The user may have more than one profile, and can switch between them with
sm_profile. This allows the user to have different configurations
and data repositories for different event sets (e.g., real time events,
scenarios, and historic events). See the
sm_profile man page for usage and a list of options.
4.1.2.2. shake¶
The primary ShakeMap program is called shake. It takes an event ID and an
optional list of modules as arguments. The modules do the work of assembling
the input data, producing interpolated grids, and deriving products from the
grids and associated metadata. See the shake man page or run
shake --help for a list of available modules. Each of the modules may have
its own command-line options; run shake help MODULE to see the help for a
given module.
The behavior of shake and some of its modules are controlled by
the configuration files shake.conf, logging.conf and products.conf.
logging.conf is largely concerned with the way logging is handled, it has
relatively few parameters that the users will want to change.
shake.conf allows the user to specify alternative locations to
search for ShakeMap modules, and to configure a list of modules that will
be run when shake is called without any modules (this is useful as a
stanard set of modules that are run routinely).
products.conf controls the behavior of some of the core modules that
produce ShakeMap products. See the comments in the config files for
additional details.
All three files should be in the user’s current profile’s
INSTALL_DIR/config directory.
shake will attempt to assess if a module is being run out of sequence
or if its dependencies are out of date. For instance, if a new data file
has been added, and the user tries to run the model module before
re-running the assemble module, shake will warn the user and
quit without running model. The user can override this behavior by
calling shake with the --force option.
4.1.2.3. shake Modules¶
Below is a description of many of the modules available to shake.
They are ordered in more or less the order they would be called. The
module select would be run first if the operator wanted to have
the ShakeMap system determine the GMPE set, IPE, GMICE, or
cross-correlation functions to use based on the event’s location and depth.
Many operators will have a fixed configuration for their regions, and will
therefore not use select.
The operator will then usually run assemble (or possibly augment)
to
create (or update) the shake_data.hdf input file, followed by running
model. The order of modules after model is usually not as important
as they most often depend upon the output of model (i.e.,
shake_result.hdf) and not upon the results of other modules.
transfer, however, will typically be run last, after the other modules
have produced their products.
To learn the details of the specific products the various modules produce, see the Users Guide section Products and Formats.
4.1.2.3.1. select¶
Please see the section Ground Motion Model Selection for
details on the way select works. select will create a file
called model_select.conf in the event’s current directory. The
configuration parameters in this file will override those set in the
sysetm-level model.conf file.
4.1.2.3.2. associate¶
The associate module checks a database of station data and searches
for ground motions that may associate with the event. If any associated
data are found, they are written to a file *_dat.xml in the event’s
current directory.
This module is only useful if the ShakeMap system is receiving
unassociated amplitudes via some method (such as PDL) and storing
that data via a program like receive_amps. Most operators will
probably not use the associate module.
4.1.2.3.3. dyfi¶
The dyfi module queries ComCat for any “Did You Feel It?” data associated
with an event and writes that data to a file in the event’s current
directory.
The event ID must be an ID that the ComCat system recognizes, thus the use of
event IDs other than those produced by NEIC or the US regional networks is
unlikely to produce results.
See shakemap.coremods.dyfi() for the module’s API documentation.
4.1.2.3.4. assemble¶
The assemble module collects event and configuration data and creates the
file shake_data.hdf. It first reads event.xml and stores it in a data
structure. sm_assemble then reads the configuration files
<install_dir>/modules.conf
<install_dir>/gmpe_sets.conf
<install_dir>/model.conf
and assembles them into a single configuration. It then reads and incorporates
<data_dir>/<evnt_id>/current>/model.conf (or model_select.conf).
Any parameter set in the event-specific model.conf will override
parameters set in the other configuration files. Note: if both
model.conf and model_select.conf exist in the event directory,
model.conf will be processed and model_select.conf will be ignored.
This behavior allows the operator to override the results of select
even if it is part of an automatic processing sequence. (That is,
select may produce a new model_select.conf file every time the
event is updated, but the operator’s model.conf will be in effect
for as long as it remains in the event’s current directory.
assemble then reads any files with a _dat.xml extension
and assembles them into a station list.
Similarly, assmeble will read a file with the _fault.txt
(or _fault.json) extension and process it as a specification of a
finite rupture.
See the Input Data Formats section for details of these input data forats.
Note: only one rupture file should be present in the event’s input directory. If more than one file exists, only the first (in lexicographic order) will we processed.
If no backups exist (i.e., event subdirectories named .backup????) then the ShakeMap history from an existing shake_data.hdf is extracted and updated. If there is no current shake_data.hdf, the history for the event is initiated. If backups do exist, then the history is extracted from the most current backup and appended with the current timestamp, originator, and version.
assemble then consolidated all of this data and writes
shake_data.hdf in the event’s current directory. If shake_data.hdf
already exists in that location, it will be overwritten.
assemble takes an optional command-line argument (-c COMMENT
or --comment COMMENT) to provide a comment
that will be added to the history for the
current version of the event’s ShakeMap. If run from a terminal,
and a comment is not provided on the command line, assemble
will prompt the user for a comment.
Run shake help assemble for more.
See shakemap.coremods.assemble() for the module’s API
documentation.

Figure 4: Data flow of the assemble module.¶
4.1.2.3.5. augment¶
The augment module behaves in a manner similar to assemble except
that it will first read shake_data.hdf from the event’s current
directory. If event.xml exists in the event’s current directory, its
data will replace the data in the existing shake_data.hdf.
The configuration data in shake_data.hdf is used as a starting point, and any configuration data from the system configuration files or the event’s model.conf (or model_select.conf) will then be added to it. Where there are conflicts, the system configuration parameters will override those found in shake_data.hdf. The event-specific configuration parameters from the local system retain the highest priority.
Data files (i.e., files in the event’s current directory that have the _dat.xml extension) will be added to any data already found in shake_data.hdf. If a finite rupture file is found in the local directory, it will replace the existing rupture data in shake_data.hdf.
The history information will be updated to reflect the update time and originator (if applicable).
As with assemble, augment takes an optional command-line
argument (-c COMMENT
or --comment COMMENT) to provide a comment
that will be added to the history for the
current version of the event’s ShakeMap. If run from a terminal,
and a comment is not provided on the command line, assemble
will prompt the user for a comment.
Run shake help augment for more.
See shakemap.coremods.augment() for the module’s API
documentation.
4.1.2.3.6. model¶
The model module reads the data in shake_data.hdf and produces an
interpolated ShakeMap. Depending upon the settings found in model.conf,
the interpolation product may be a grid or a set of points. See
model.conf for additional options and documentation. The model.conf
file in the user’s current profile (i.e., INSTALL_DIR/config/model.conf)
will be read first, and then if model.conf or model_select.conf exists
in the event’s current directory, then the parameters set therein will
override those in the profile’s model.conf. If both model.conf and
model_select.conf exist in the event’s current directory, model.conf
will be processed and model_select.conf will be ignored. model also reads
the configuration files gmpe_sets.conf and modules.conf, which
reside in the current profile’s INSTALL_DIR/config directory. See
the documentation within those files for more information.
A great deal of this manual is devoted to the way the interpolation is
performed, and the effect of various configuration options. See the
relevant sections for more. In particular, the section
Data Processing
goes into detail on the way the model module works.
model writes a file, shake_result.hdf, in the products
subdirectory of the event’s current directory.
See the section Products and Formats of the Users Guide for more on the
format and content of shake_result.hdf.
See shakemap.coremods.model() for the module’s API
documentation.
4.1.2.3.7. contour¶
contour reads an event’s shake_result.hdf and produces iso-seismal
contours for each of the intensity measure types found therein. The contours
are written as GeoJSON to files called cont_<imt_type>.json in the event’s
current/products subdirectory.
See shakemap.coremods.contour() for the module’s API documentation..
4.1.2.3.8. coverage¶
coverage reads an event’s shake_result.hdf and produces low-, medium-,
and high-resolution “coverages” for interactive maps and plots in the
CoverageJSON format, and places
them in the current/products subdirectory.
See shakemap.coremods.coverage() for the module’s API documentation..
4.1.2.3.9. gridxml¶
gridxml reads an event’s shake_result.hdf and produces the ShakeMap 3.5
files grid.xml and uncertainty.xml. Note that these files will eventually
become deprecated in favor of the new shake_result.hdf file.
See the products section of this manual for more on these files.
Note that the use of these files is
deprecated. System designers should extract the relevant information
directly from shake_result.hdf.
See the section Products and Formats of the Users Guide for more on the
format and content of shake_result.hdf.
See shakemap.coremods.gridxml() for the module’s API
documentation.
4.1.2.3.10. info¶
info reads an event’s shake_result.hdf and produces info.json,
which contains metadata about the ShakeMap.
See shakemap.coremods.info() for the module’s API
documentation.
4.1.2.3.11. kml¶
kml reads shake_result.hdf and produces a file, shakemap.kmz
which is a self-contained file of geographic layers suitable for
reading into Google Earth. The layers include an MMI overlay and MMI
polygons, contours of MMI and the other IMTs found in shake_result.hdf,
station locations and data, and the event’s epicenter.
4.1.2.3.12. mapping¶
mapping reads an event’s shake_result.hdf and produces a set of
maps of the IMTs in both JPEG and PDF format. Also produced is an abstract
thumbnail image of MMI which may be used as a symbolic logo or pin for
the event’s ShakeMap products. The module also produces a PNG intensity
“overlay” and its associated world file..
See shakemap.coremods.mapping() for the module’s API documentation.
See the configuration file products.conf for information on configuring
the mapping module.
4.1.2.3.13. plotregr¶
When model runs, it produces a set of curves of the selected GMPE vs.
distance, as well as a set of distance metrics [e.g., epi- and hypo-central
distances, rupture distance, and Joyner-Boore distance (where the rupture
is unknown, these last two distance metrics are replaced with estimated
fault distances using the point-source to finite-rupture methodology
discussed in the section Finite-rupture Approximations.)]
plotregr uses the ground-motion curves produced by model to
make plots of the GMPE’s predicted
ground motion [on “rock” (i.e., Vs30=760 m/s) and “soil” (i.e., Vs30=180
m/s), plotted as green and red lines, respectively]
as a function of distance for each
output IMT, along with
the seismic and macroseismic data for that IMT.
The +/- 1 standard
deviation lines are also plotted. The station and dyfi data are plotted at
their computed distance from the source. If no finite fault is available for
the map, then the approximated point-source to finite-fault distance
is used.
The plotregr module and its plots are fairly simplistic and of limited
utility. The interactive residual plots deployed on the USGS web site make
use of the much richer data found in the station file, and are a far better
tool for studying the characteristics of the data,
4.1.2.3.14. raster¶
raster reads an event’s shake_result.hdf and produces GIS
raster files of the mean and standard deviation for each of the
IMTs in shake_result.hdf.
See shakemap.coremods.raster() for the module’s API
documentation.
4.1.2.3.15. rupture¶
rupture reads an event’s shake_result.hdf and produces a
file, rupture.json containing the coordinates of the rupture
plane(s) supplied via the input file <>_fault.txt or <>_fault.json.
See shakemap.coremods.rupture() for the module’s API
documentation.
4.1.2.3.16. shape¶
shape reads an event’s shake_result.hdf and produces a set of
ESRI-style shape files for the ground motion parameters found therein.
The shape files are zipped together with supporting .lyr, .prj, and
metadata XML files and distributed as a file called shape.zip. The
use of the shape files is deprecated and it is preferable to use the
ESRI raster file (see the raster section, above.)
4.1.2.3.17. stations¶
stations reads an event’s shake_result.hdf and produces a
JSON file, stationlist.json, of the input station data. The output
JSON also contains predicted values (on “rock” and “soil”), inter- and
intra-event uncertainties for each type of prediction, converted amplitudes
(PGM to MMI or MMI to PGM), distance metrics, etc.
See shakemap.coremods.stations() for the module’s API
documentation.
4.1.2.3.18. transfer¶
There are three main transfer programs: transfer_email (which sends
email to a list of users), transfer_pdl (which inserts the ShakeMap
products into the PDL system), and transfer_scp (which does a
local or remote copy of the products to another filesystem). These programs
allow the operator to transfer ShakeMap products to
other systems via PDL or ssh, and notify users with an email with the event
summary information. See the documentation in transfer.conf
for details on configuring the transfer_* programs.
See shakemap.coremods.transfer() for the module’s API
documentation.
4.1.2.4. Miscellaneous shake Modules¶
The modules below have special purposes and are generally not used in routine processing.
4.1.2.4.1. history¶
The hisotry module will attempt to read the ShakeMap history
information stored in the event’s shake_data.hdf or backup files
and print it to the screen.
4.1.2.4.2. save¶
The save module generates a new backup???? directory with the
contents of the event’s current directory. It is useful for preserving
intermediate results.
4.1.2.4.3. sleep¶
The sleep module will cause the calling process to sleep for a
specified number of seconds. It may be useful under certain circumstances.
4.1.3. Additional Programs¶
ShakeMap provides a few auxiliary programs that may occasionally be useful.
4.1.3.1. getdyfi¶
getdyfi is a standalone program implementing the dyfi module’s
functionality. See the getdyfi man page for usage and a
list of options.
4.1.3.2. sm_compare¶
Allows the user to compare two ShakeMaps by making images of their difference and ratio.
See the sm_compare man page for usage and a list of options.
4.1.3.3. sm_create¶
sm_create queries the NEIC ComCat database for ShakeMap data
associated with an event and writes that data into the event’s
local current directory. The event will then be available for
local processing.
See the sm_create man page for usage and a list of options.
4.1.3.4. sm_migrate¶
Migrates a directory of ShakeMap 3.5 data files into ShakeMap v4 inputs. The migration of GMPEs is configurable via the migrate.conf configuration file.
See the sm_migrate man page for usage and a list of options.
4.1.3.5. sm_queue¶
A daemon process to receive messages from external systems for the
triggering and cancellation of ShakeMap runs. See the section
Queueing Events for more detail. The behavior
of sm_queue is controlled by the queue.conf configuration
file. This file is not copied to new profiles by default, so it
may be retrieved from the source directory
<shake_install_dir>/shakemap/data.
See the sm_queue man page for usage and a list of options.
4.1.3.6. receive_amps, receive_origins, and associate_amps¶
receive_amps and receive_origins are intended to be run
by a configured instance of the USGS’s Product
Distribution system (PDL) to inform sm_queue of new origins and
unassociated amplitudes. They are, therefore, of limited utility
to most users, however they may serve as guides as to writing
similar programs for other systems.
associate_amps is a utility program to associate the
unassociated amplitudes with origins, and to create ShakeMap
input files with those that associate. Again, this will be of
limited utility to users not running PDL.
4.1.3.7. run_verification¶
Runs a set of simple verification tests and displays the results.
The resulting plots may be compared to those found in the
documentation section Verification.
run_verification is a shell script. See the source file for
usage and notes.
4.1.3.8. sm_batch¶
Will run a list of events specified in a text file containing one event ID per line.
4.1.3.9. sm_check¶
Will check the user’s configuration files for certain types of errors.
4.1.3.10. sm_rupture¶
Will create or convert a rupture file for ShakeMap v4. Run the program with the “–help” option for an explanation and a list of options.